AWS Elastic Disaster Recovery minimizes downtime and data loss. Backup and Disaster Recovery with fast, reliable recovery of on-premises and cloud-based applications using affordable storage, minimal compute, and point-in-time recovery
What is Disaster Recovery on AWS?
Quickly recover operations after unexpected events such as software issues or data center hardware failures. AWS DRS enables RPOs of seconds and RTOs of minutes.
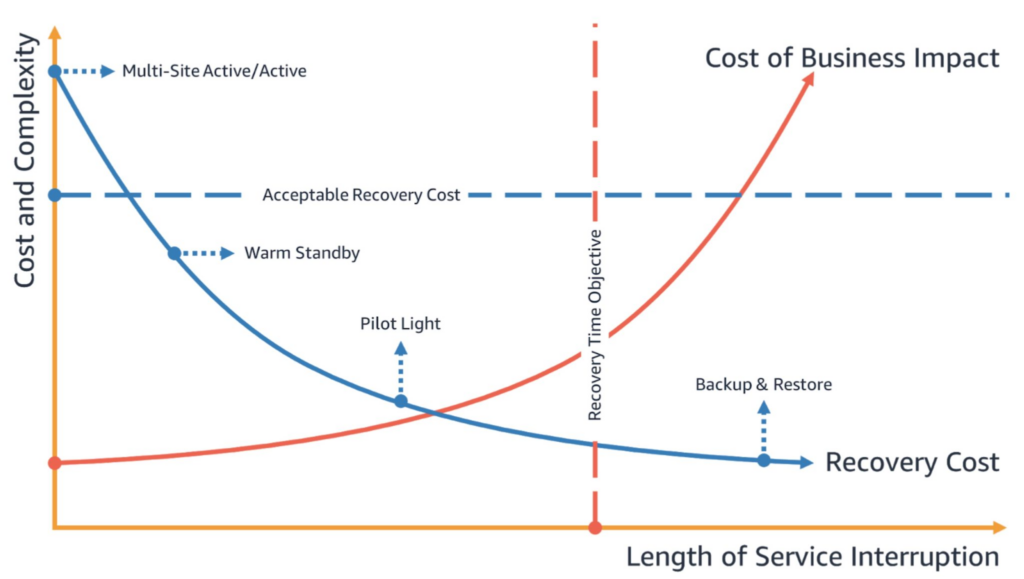
AWS offers four main disaster recovery (DR) strategies you can adopt to create backups that are available during disaster events. Each strategy has a progressively higher cost and complexity but lower recovery times
On-premises to AWS:
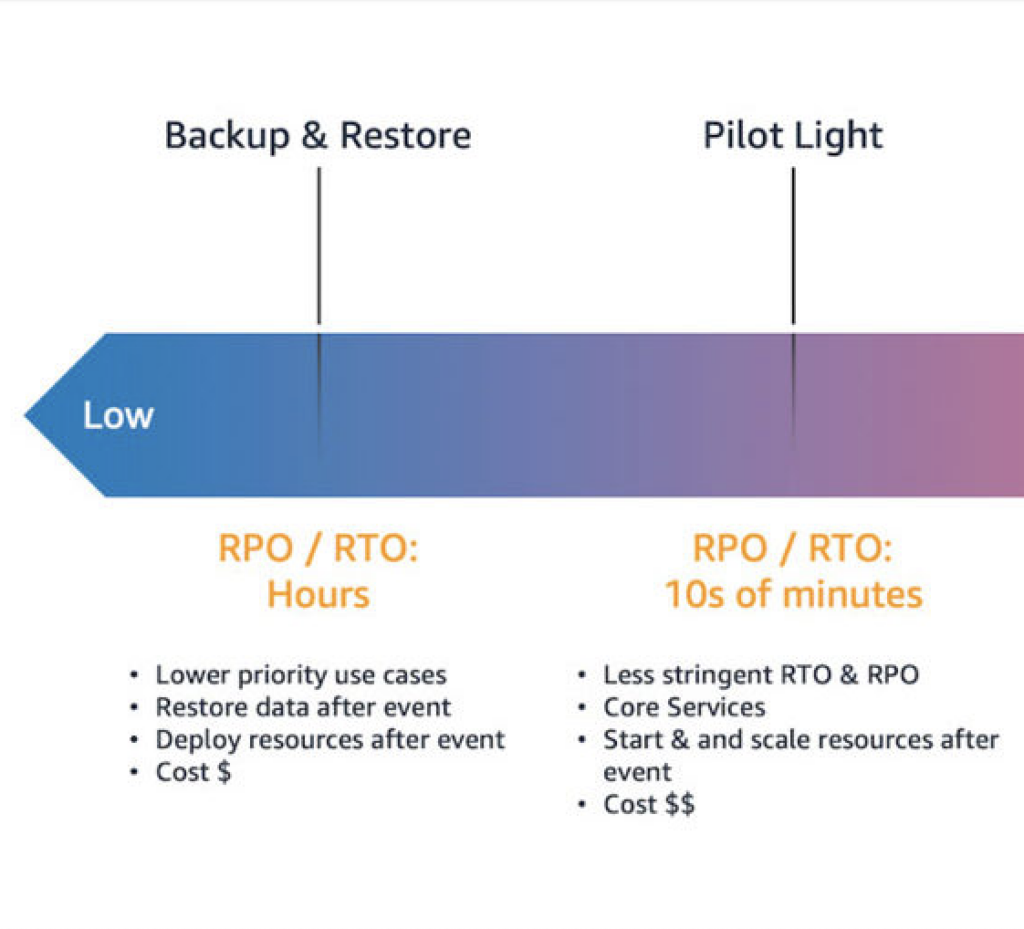
Backup and restore – involves backing up your systems and restoring them from backup in case of disaster.
Pilot light – involves running core services in standby mode and triggering additional services as needed in case of disaster.
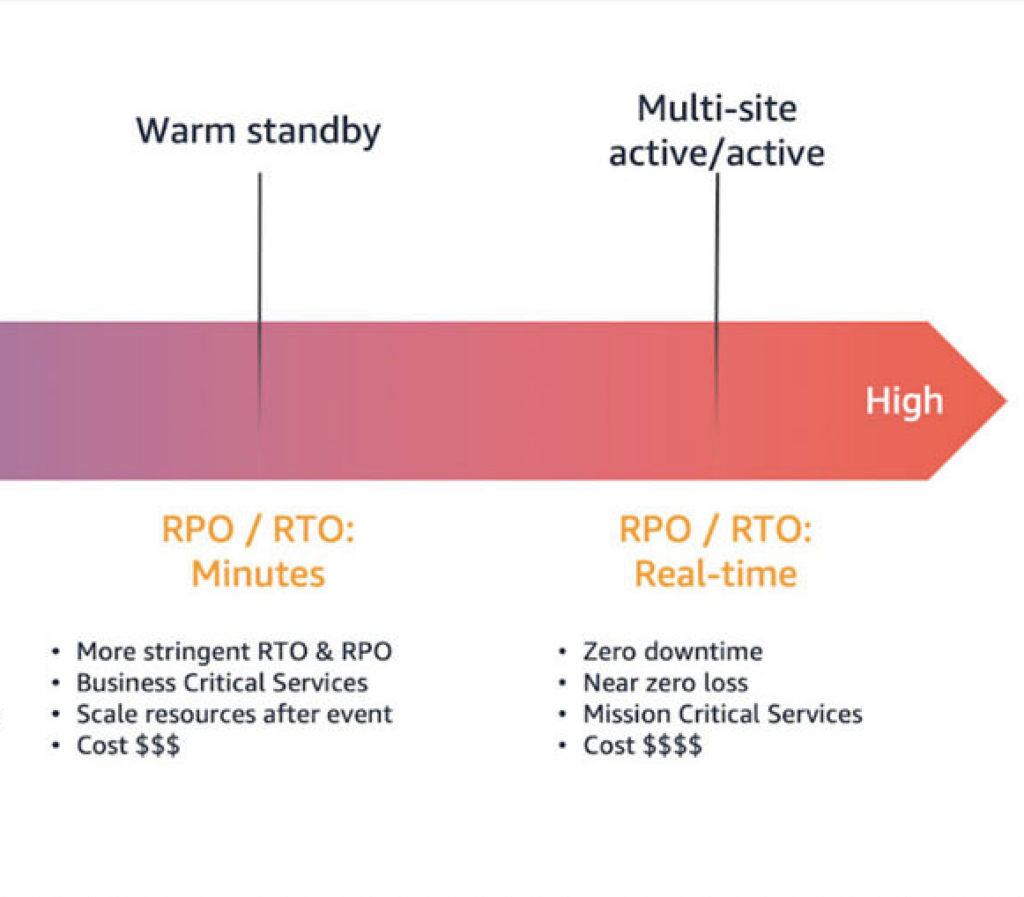
Warm standby – involves running a full backup system in standby mode, with live data replicated from the production environment.
Multi-site active/active – running a full, secondary production system, ready to serve traffic when needed
Each DR strategy on AWS offers different recovery time objectives (RTO) and recovery point objectives (RPO). Strategies are designed at several ranges of costs and complexities.
Generally, the more complex and highly available DR strategies come with higher costs. Less complex strategies that provide lower availability are more cost-effective.
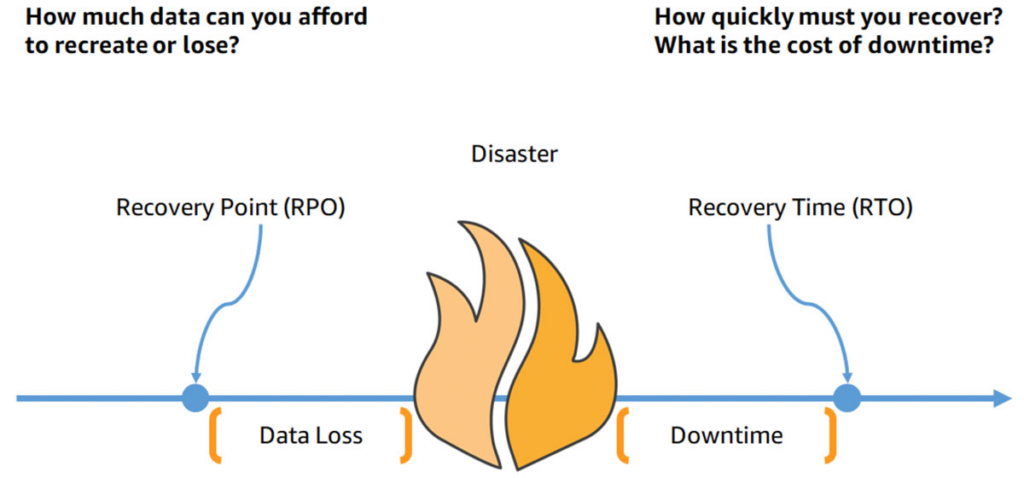
The longest time that may pass since the last backup window. For example, if the district backs up files once per hour, it can lose one hour of data. The RPO is 60 minutes
How do the four recovery strategies compare?
Backup & restore provides the lowest cost, but the longest RTO
Pilot light provides a medium cost and RTO
Warm standby provides a high cost and low RTO
Multi-site active/active provides the highest cost and a near-zero RTO
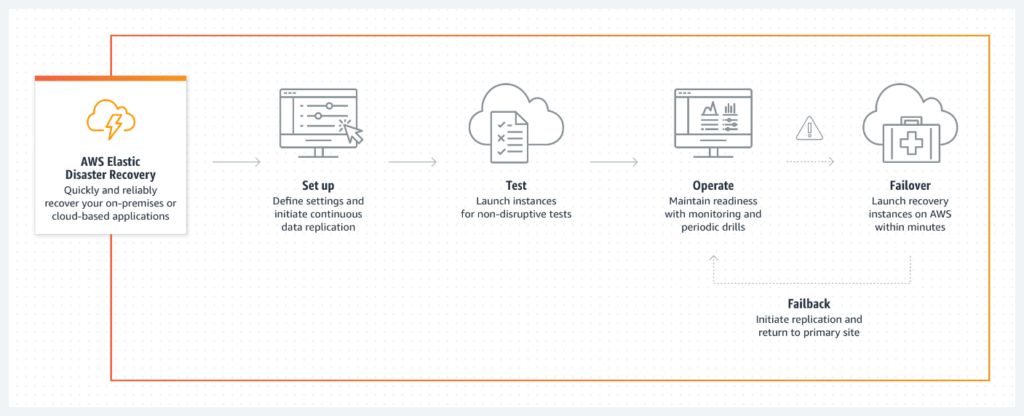
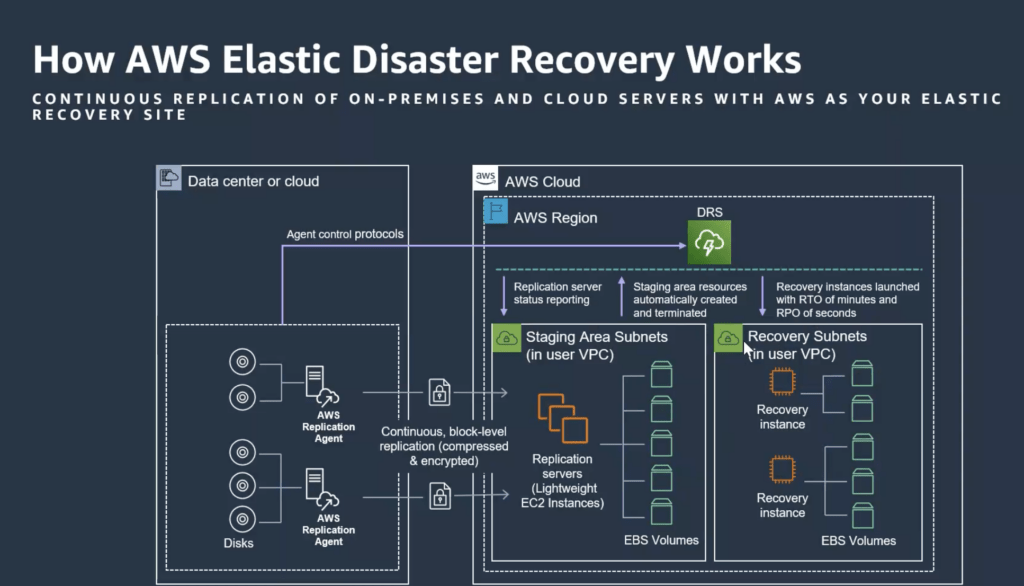
Set up AWS Elastic Disaster Recovery on your source servers to initiate secure data replication.
Data is replicated to a staging area subnet in your AWS account in the AWS Region you select.
The staging area design reduces costs by using affordable storage and minimal compute resources to maintain ongoing replication.
You can perform non-disruptive tests to confirm that implementation is complete.
During normal operations, maintain readiness by monitoring replication and periodically performing recovery and failback drills.
If you need to recover applications, you can launch recovery instances on AWS within minutes, using the most up-to-date server state or a previous point in time.
After your applications are running on AWS, you can choose to keep them there, or you can initiate data replication back to your primary site when the issue is resolved.